
공부하자
머신러닝 - 기초(Numpy, Pandas, ...) 본문
머신러닝이란? 데이터를 기반으로 패턴을 학습하고 결과를 예측하는 알고리즘 기법
머신러닝 분류
- 지도학습 : 분류, 회귀, 추천시스템, 시각/음성 감지/인지, 텍스트 분석, NLP
- 비지도학습 : 클러스터링, 차원 축소, 강화학습
## 머신러닝 패키지
- 머신러닝 패키지 : Scikit-Learn
- 행렬/선형대수/통계 패키지 : NumPy, SciPy
- 데이터 핸들링 : Pandas
- 시각화 : Matplotlib, Seaborn
그 외 설치
- Anaconda
- 모든 실습은 Jupyter Notebook 기반으로 실시
1. Numpy
- ndarray : Numpy 기반 데이터 타입
- array() : 파이썬의 리스트와 같은 다양한 인자를 입력 받아서 ndarray로 변환
- shape() : ndarray의 차원과 크기를 tuple 형태로 출력
- ndim() : ndarray의 차원 출력
★ Numpy ndarray 배열의 차원

## ndarray 내의 데이터 값
: 숫자값(int, unsigned int, float, complex), 문자값, 불 값
: ndarray 내의 데이터 타입은 연산의 특성 상 같은 데이터 타입만 가능
: 데이터 타입이 다른 경우 크기가 큰 데이터 타입으로 형 변환 일괄 적용

- dtype : ndarray 내의 데이터 타입 확인
- astype() : ndarray 내의 데이터 타입 변경
★ 파이썬 내장 자료형
: 정수(int), 실수(float), 문자열(string), 리스트, 딕셔너리
★ unsigned int
: 부호가 없는 정수
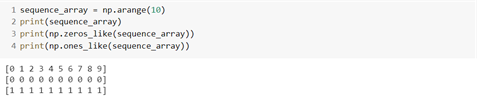
## ndarray를 편리하게 생성하기 – arange(), zeros(), ones()
- arange() : 0부터 (함수 인자 값-1)까지 순차적으로 ndarray 데이터값으로 변환
- zeros() : tuple 형태의 shape를 입력하면 모든 값을 0으로 채운 ndarray 반환
- ones() : tuple 형태의 shape를 입력하면 모든 값을 1로 채운 ndarray 반환
- zeros(), ones()의 default 데이터값 : float64
★ np.zeros_like(ndarray), np.ones_like(ndarray)
: ndarray의 shape에 해당하는 zeros() 또는 ones() ndarray 반환
## ndarray의 차원과 크기를 변경하는 reshape()
- reshape()
: ndarray를 특정 차원 및 크기로 변환
: 인자로 -1을 사용하면 기존 ndarray와 호환되는 새로운 shape로 변환
: reshape(-1, 1) 형태로 자주 사용
## ndarray의 데이터 세트 선택하기 – 인덱싱(Indexing)
- 단일 값 추출
: 원하는 위치의 인덱스값 지정
: 2차원의 경우, 콤마(,)로 분리된 로우, 칼럼 위치의 인덱스를 통해 접근
★ axis 0, axis 1
- axis 0 : row(행) 방향 축 (행 목록)
- axis 1 : column(열) 방향 축 (열 목록)

## Slicing
: ‘:’ 기호를 통해 연속한 데이터 추출
: 시작 인덱스에서 (종료 인덱스-1) 위치에 있는 데이터의 ndarray 반환
: 시작 인덱스 생략할 경우 맨 처음 인덱스인 0으로 간주
: 종료 인덱스 생략할 경우 맨 마지막 인덱스로 간주
- 팬시 인덱싱
: 인덱스 집합을 지정하면 해당 위치의 인덱스에 해당하는 ndarray 반환
(=연속하지 않는 여러 개의 인덱스를 지정하여 데이터 추출)
- 불린 인덱싱
: 조건 필터링, 검색
## 행렬의 정렬 – sort(), argsort()
- sort()
: np.sort() 원본 행렬 유지, 정렬된 행렬 반환
: ndarray.sort() 원본 행렬을 정렬한 형태로 반환, 반환값 None
: default 오름차순 정렬, [::-1]을 통해 내림차순 정렬
★ [::-1]의 의미
- arr[A:B:C] : 인덱스 A부터 B까지 C의 간격으로 배열 생성
- [::-1] : 처음부터 끝까지 -1칸 간격으로(=역순 출력)

★ 2차원 ndarray 칼럼 방향 내림차순 정렬 방법

- argsort()
: 정렬된 행렬의 원본 행렬 인덱스를 ndarray형으로 반환
: 내부에서, 행렬을 정렬한 다음, 원본 행렬 인덱스가 어떻게 정렬되었는지를 가져온다.
ex. 원본 행렬이 3(0), 1(1), 9(2), 5(3) 였으면(괄호 밖은 요소값, 괄호 안은 index를 나타냄),
정렬되면 1(1), 3(0), 5(3), 9(2)가 됨, 이 때 index는 원래 0, 1, 2, 3이었던게 정렬되면서 1, 0, 3, 2 순으로 정렬된다.
--> 1, 0, 3, 2를 반환함.
: 활용 방법

: 왜 필요한가? numpy의 ndarray는 pandas처럼 메타 데이터를 가질 수 없다(예 : index값, column값 등)
그래서 ndarray로 dataframe처럼 사용하려면 메타 데이터 array, 그리고 값(데이터) array를 따로 가져야 하는데.
data를 sort한 다음에, sort된 데이터 대로 메타 데이터도 sort하려면 argsort가 필요함!
## 선형대수 연산 – 행렬의 내적과 전치 행렬 구하기
- np.dot() : 행렬 내적 연산
- np.transpose() : 전치 행렬 연산
2. Pandas
## 파일을 DataFrame으로 로딩, 기본 API
- DataFrame : 행, 열로 이루어진 2차원 데이터를 담는 구조체
- Index : 개별 데이터를 고유하게 식별하는 Key값
- Series
: 칼럼이 하나인 구조체
: DataFrame[‘칼럼명’] => Series 형태로 특정 칼럼 데이터 세트 반환
- read_csv(), read_table(), read_fwf() : 파일 포맷 변환
- Filepath 인자 : 로드하려는 데이터 파일의 경로를 포함한 파일명 로딩
★ 파일 경로 확인 방법
: 파일 오른쪽 마우스 클릭>속성>위치
- head() : DataFrame의 맨 앞에 있는 N개의 로우 반환
- info() : 총 데이터 건수, 데이터 타입, Null 건수 반환
- describe()
: 칼럼별 숫자형 데이터값의 n-percentile 분포도, 평균값, 최대값, 최소값 반환
- value_counts()
: Series 객체에서 지정된 칼럼의 데이터값 건수 반환
: 많은 건수 순서로 정렬되어 Series 객체로 반환
## DataFrame과 리스트, 딕셔너리, ndarray 상호 변환
- ndarray, 리스트, 딕셔너리 → DataFrame
: 일반적으로 DataFrame 변환 시 칼럼명 지정
: pd.DataFrame()
- DataFrame → ndarray, 리스트, 딕셔너리
: values, tolist(), to_dict()
: to_dict() 인자로 ‘list’ 입력 시 딕셔너리 값이 리스트형으로 반환
## DataFrame의 칼럼 데이터 세트 생성과 수정
- DataFrame[‘칼럼명’] = 값

## DataFrame 데이터 삭제
- drop(labels, axis, inplace)
- labels
: 삭제할 칼럼명
- axis
: axis=0(지정된 로우 삭제, 이상치 데이터 삭제하는 경우 사용)
: axis=1(지정된 칼럼 삭제, 일반적으로 많이 사용)
- inplace
: inplace=False(원본 유지, 삭제된 결과 반환)
: inplace=True(원본에서 삭제, None 반환)
★ inplace=True 지정 후 다시 DataFrame 객체로 할당하지 않도록 주의
## Index 객체
- DataFrame.index : 인덱스 객체 반환
- 인덱스 변경 불가능
- reset_index()
: 새로운 인덱스를 연속 숫자형으로 할당하고, 기존 인덱스는 새로운 칼럼명‘index’로 추가
: 연속된 int 숫자형 데이터가 아닌 인덱스를 다시 연속 int로 만들 때 사용
: drop=True로 설정하면 기존 인덱스는 새로운 칼럼으로 추가되지 않고 삭제
## 데이터 셀렉션 및 필터링
- iloc() (index location)
: 위치 기반 인덱싱
: 명칭 입력 시 오류
: 불린 인덱싱 제공 X
- loc() (location)
: 명칭 기반 인덱싱
: 슬라이싱 적용 시 (종료값-1)이 아니라 종료값까지 포함
: 불린 인덱싱 제공
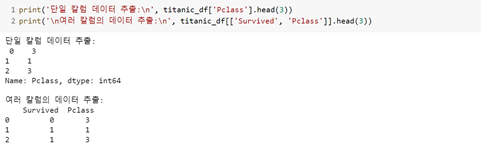
★ (p.73) DataFrame에서 칼럼 추출 시 괄호 2개 작성하는 이유
- 여러 개의 칼럼에서 데이터를 추출하기 위해서 리스트 객체 이용
## 정렬, Aggregation 함수, GroupBy 적용
- 정렬
: sort_values(by, ascending, inplace)
: by(해당 칼럼으로 정렬 수행)
: ascending=True(오름차순 정렬) / ascending=False(내림차순 정렬)
: inplace=True(호출된 DataFrame의 정렬 결과를 그대로 적용)
- Aggregation 함수
: min(), max(), sum(), count()
: DataFrame에서 바로 호출할 경우 모든 칼럼에 aggregation 함수 적용
- GroupBy
: groupby(by)
: 특정 칼럼을 대상으로 groupby 진행
: groupby() 결과에 aggregation 함수를 호출할 경우 대상 칼럼을 제외한 모든 칼럼에 aggregation 함수 적용
: 특정 칼럼에 aggregation 함수를 적용하기 위해서 필터링 필요

2-2. 결손 데이터 처리하기
- isna()
: NaN 여부 확인
: 결측값이 많은 데이터는 신뢰도가 떨어지기 때문에 결측값 반드시 확인
- fillna()
: 결손 데이터값 대체
: 실제 데이터 세트 변경을 위해서 fillna()를 이용해 반환값을 다시 받거나 inplace=True로 설정
## apply lambda 식으로 데이터 가공
- apply lambda : 레코드 별로 데이터 가공
- lambda if절의 경우 if식보다 반환값을 먼저 기술

<파이썬 머신러닝 완벽 가이드> 책 기반 작성
'머신러닝' 카테고리의 다른 글
| 머신러닝 - 회귀 (0) | 2021.06.27 |
|---|---|
| 머신러닝 - 성능 평가, 분류 (0) | 2021.06.27 |
| 머신러닝 - 사이킷런, 모델 Selection, 데이터 전처리 (0) | 2021.06.27 |
| 머신러닝 with 파이썬 머신러닝 완벽 가이드 (0) | 2021.06.27 |


