
공부하자
실습 - sklearn 데이터셋 : Boston (1) 본문
import numpy as np
import pandas as pd
import tqdm
import os
import sklearn.datasets
load_list = list(filter(lambda x: 'load_' in x, dir(sklearn.datasets)))
# lambda x: 'load_' in x => x안에 'load_'라는 문자열이 있으면 True를 반환
# filter(func, iterable) => iterable의 요소들이 func함수를 거쳐서, 그 결과가 True인 것만 반환
load_list
['load_boston',
'load_breast_cancer',
'load_diabetes',
'load_digits',
'load_files',
'load_iris',
'load_linnerud',
'load_mlcomp',
'load_sample_image',
'load_sample_images',
'load_svmlight_file',
'load_svmlight_files',
'load_wine']from sklearn.datasets import *
boston = load_boston()
breast = load_breast_cancer()
diabetes = load_diabetes()
digits = load_digits()
iris = load_iris()
linnerud = load_linnerud()
wine = load_wine()위의 7개 데이터셋으로 시각화, 모델링 등 실습해보겠음
1. 보스턴 집값 데이터셋
# sklearn의 dataset은 Dataframe형태가 아니고 dictionary와 비슷한 데이터구조이다.
# 그래서 dataframe으로 먼저 바꿔줌
boston_df = pd.DataFrame(boston.data, columns = boston.feature_names)
boston_df['target'] = boston.target
boston.DESCR # 데이터에 대한 설명이 들어있는 key0. feature 설명
- CRIM : town 별 1인당 범죄율
- ZN : 25,000 제곱 피트 이상의 주거지역 비율
- INDUS : town 별 비상업지역 비율?
- CHAS : 강이 근처에 있으면 1, 없으면 0
- NOX : nitric oxides 농도 (part per 10million)
- RM : 주거시설당 방 개수 평균
- AGE : 1940년 이전에 지어진, 오너가 거기 살고 있는 집 비율?
- DIS : 5개의 보스턴 고용중심지까지의 weighted distance(어떻게 가중치를 사용했는지?)
- RAD : 외곽 고속도로와의 접근성 표기
- TAX : 만 달러당 세금비율?
- PTRATIO : town 별 학생/교사 비율
- B : 흑인 비율과 관련된 feature.
- LSTAT : 하위계층비율
- MEDV : 본인 소유의 주택들 가격 (1000달러 단위)
# 해야 할 것들
- 결측치가 있는지 확인하기
- 이상치가 있는지 확인하기
- 카테고리컬한 데이터인지 확인(ZN, INDUS, RAD)
- 변수 사이에 연관성 확인하기
- 차원 축소 고려하기(변수 숫자가 크지 않아서 꼭 필요하진 않을 것 같지만)
- 그 외 배경지식을 이용한 변수 활용
1. 데이터셋 확인
boston_df.head(10)| 0.00632 | 18.0 | 2.31 | 0.0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1.0 | 296.0 | 15.3 | 396.90 | 4.98 | 24.0 |
| 0.02731 | 0.0 | 7.07 | 0.0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2.0 | 242.0 | 17.8 | 396.90 | 9.14 | 21.6 |
| 0.02729 | 0.0 | 7.07 | 0.0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2.0 | 242.0 | 17.8 | 392.83 | 4.03 | 34.7 |
| 0.03237 | 0.0 | 2.18 | 0.0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3.0 | 222.0 | 18.7 | 394.63 | 2.94 | 33.4 |
| 0.06905 | 0.0 | 2.18 | 0.0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3.0 | 222.0 | 18.7 | 396.90 | 5.33 | 36.2 |
| 0.02985 | 0.0 | 2.18 | 0.0 | 0.458 | 6.430 | 58.7 | 6.0622 | 3.0 | 222.0 | 18.7 | 394.12 | 5.21 | 28.7 |
| 0.08829 | 12.5 | 7.87 | 0.0 | 0.524 | 6.012 | 66.6 | 5.5605 | 5.0 | 311.0 | 15.2 | 395.60 | 12.43 | 22.9 |
| 0.14455 | 12.5 | 7.87 | 0.0 | 0.524 | 6.172 | 96.1 | 5.9505 | 5.0 | 311.0 | 15.2 | 396.90 | 19.15 | 27.1 |
| 0.21124 | 12.5 | 7.87 | 0.0 | 0.524 | 5.631 | 100.0 | 6.0821 | 5.0 | 311.0 | 15.2 | 386.63 | 29.93 | 16.5 |
| 0.17004 | 12.5 | 7.87 | 0.0 | 0.524 | 6.004 | 85.9 | 6.5921 | 5.0 | 311.0 | 15.2 | 386.71 | 17.10 | 18.9 |
- 결측치 확인 : 결측치 없음
boston_df.isnull().sum()
CRIM 0
ZN 0
INDUS 0
CHAS 0
NOX 0
RM 0
AGE 0
DIS 0
RAD 0
TAX 0
PTRATIO 0
B 0
LSTAT 0
target 0
dtype: int64
# sum(1)하면 axis = 1이라는 뜻인 듯, index 별로 각 column 값들의 합계를 구함
- 이상치 확인
모든 column(target 제외)에 대해 boxplot 그려봤음
for col in range(len(boston_df.columns)-1):
plt.figure(figsize = (10, 7))
plt.boxplot(boston_df.iloc[:, col])
plt.show()그리긴 그려 봤는데 그려서 뭘 얻어내야 하는지는 잘 모르겠다.
여러가지 타입이 있었는데
1) 이상하게 생기긴 함, 근데 그렇다고 뭔가 해줘야 하는 건지는 잘 모르겠음. 윗수염을 넘는 데이터들이 아주 많음


2) 그냥 잘 아는 Boxplot 모양 나옴

3) 밖으로 삐져나온 데이터는 빼도 될 거 같은 플롯, DIS, PTRATIO, LSTAT

이상치의 기준은 뭔가요? -> 박스플롯에서 윗수염, 아래수염을 넘는 값들을 이상치로 보통 판단한다.
CRIM, ZN의 경우 직선을 넘는 값들도 꽤 있으니까 전부 이상치라고 보고 제거하기엔 좀 불안하다.
DIS, PTRATIO, LSTAT에서는 그리 많지 않으므로 이 컬럼들에서 위 직선(Upper whisker)을 넘는 데이터들을 제거하고 나머지 데이터들로 분석해 보겠음.
데이터를 제거했을 경우랑 제거하지 않았을 경우를 나중에 비교해보기.
# Upper whisker, Lower whisker를 직접 계산하는 방법
# np.percentile(array, %point)를 통해 Q1, Q3를 계산한다.
Q3 = np.percentile(boston_df.DIS.values, 75)
Q1 = np.percentile(boston_df.DIS.values, 25)
# Upper whisker = Q3 + 1.5IQR, Lower whisker = Q1 - 1.5IQR 식을 이용
Upper = Q3 + 1.5*(Q3-Q1)
Lower = Q1 - 1.5*(Q3-Q1)
# Plot 보면 Lower whisker 아래의 데이터는 없었으므로, boolean mask는 upper에만 붙여서
drop_index = boston_df[boston_df.DIS>Upper].index
# 만약 Lower whisker 아래의 데이터도 있어서 제거하고 싶으면, 아래처럼.
drop_index = boston_df[(boston_df.DIS>Upper)|(boston_df.DIS<Lower)].index
# drop_index에 해당하는 데이터를 없애주기, axis = 0으로 해야 index가 사라짐.
# axis = 1이면 column이 사라짐
boston_df.drop(drop_index, axis = 0, inplace = True)위와 같은 알고리즘으로 걸러낸다.
# drop할 index를 box-whisker의 윗수염, 아랫수염 기준으로 반환하는 함수
def drop_index(df, col):
Q3 = np.percentile(df[col].values, 75)
Q1 = np.percentile(df[col].values, 25)
Upper = Q3 + 1.5*(Q3-Q1)
Lower = Q1 - 1.5*(Q3-Q1)
drop_idx = df[(df[col]>Upper)|(df[col]<Lower)].index
return drop_idx
boston_df.drop(drop_index(boston_df, "DIS"), axis = 0, inplace = True)PTRATIO, LSTAT 컬럼에도 똑같이 해준다.
# index 혹시나 다른 거 없앨 수도 있으니까 reset 해주기
boston_df.reset_index(drop = True)
boston_df.drop(drop_index(boston_df, "PTRATIO"), axis = 0, inplace = True)
boston_df.reset_index(drop = True)
boston_df.drop(drop_index(boston_df, "LSTAT"), axis = 0, inplace = True)
boston_df.reset_index(drop = True)
- 카테고리컬 데이터 확인
CHAS는 데이터 설명에서 이미 0 or 1의 binary 변수라는걸 확인
ZN, INDUS, RAD의 값들 확인
boston_df.ZN.value_counts()
boston_df.INDUS.value_counts()
boston_df.RAD.value_counts()결과 : ZN, INDUS는 값들을 연속적이라고 봐도 괜찮을 것 같음,
RAD는
24.0 127
4.0 105
5.0 102
3.0 38
6.0 26
8.0 24
2.0 21
1.0 20
7.0 17
Name: RAD, dtype: int64이렇게 나왔음. 24가 127개로 엄청 많고, 그 아래는 다 10 이하... RAD는 뭐 주요 도로와의 접근성에 관련된 변수
연속적인 값을 가진다고 일단 생각해놓고, 24인 것과 아닌 것들로 그룹화해서 해볼 수도 있는 것 같음
- 변수 간 연관성 확인
피어슨 상관계수를 이용함
corr_df = boston_df[list(filter(lambda x: x not in ["CHAS"], boston_df.columns))].corr()
# 원하지 않는 것만 간단하게 제외하는 이거 말고 더 쉬운 방법이 있을거 같은데 일단 이렇게함

그럼 이런 모양의 dataframe이 나오는데, 이걸 sns heatmap을 통해 시각화.
plt.figure(figsize = (14, 10))
sns.heatmap(corr_df, annot = True)
plt.show()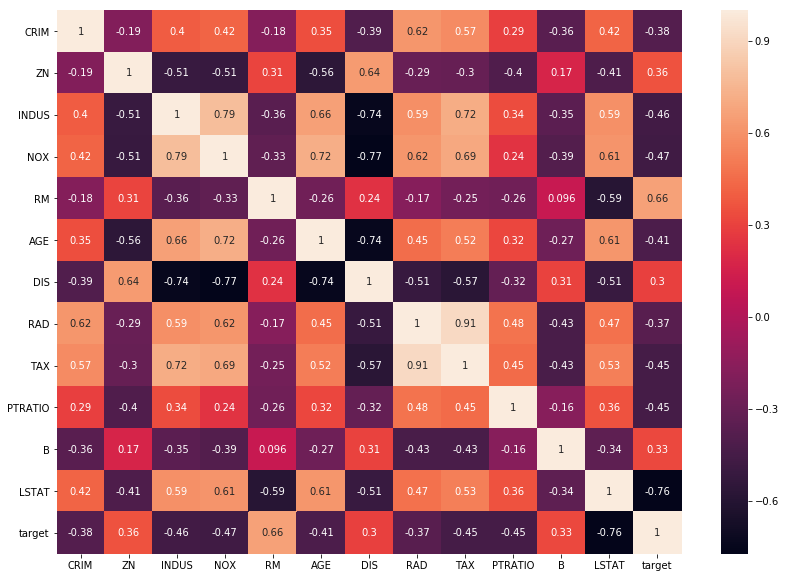
TAX 열과 RAD 열은 상관관계가 0.91로 매우 크다.
검은색(상관관계가 -1에 가까운 것들) 도 상관관계가 크다고 간주하는 건가?
다음으로는 전체 변수에 대한 pairplot을 그려본다.
plt.figure(figsize = (14, 10))
sns.pairplot(boston_df)
plt.show()
- 너무 많고 크다.
- TAX와 RAD는 상관관계 분석에서는 큰 양의 상관관계를 가지는 것으로 나왔는데, pairplot을 보면 이걸 양의 상관관계라고 할 수 있는지 의문
- TAX와 DIS도 음의 선형 관계가 있는 듯.
- target(MEDV)와 LSTAT이 음의 관계가 있는 것 같고, 선형은 아니지만 곡선의 형태가 눈에 보인다.
- TAX & RAD

접근성이 높은 집(RAD = 24) 는 전부 재산세율 값이 매우 컸다.
오른쪽 아래에 있는 점은 어떤 집인지 확인해보자
boston_df[(boston_df.RAD<5) & (boston_df.TAX>700)]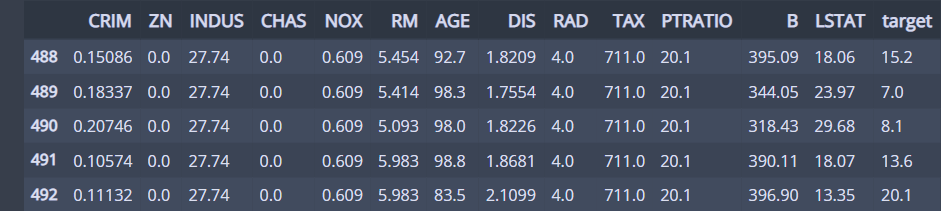
5개로 적어서 상관관계 분석에선 큰 영향이 없었던 것 같음.
target값에 일관성 있지는 않고,
- TAX와 DIS와의 상관관계

오래된 건물일수록 임자가 없는 요충지에 다른 건물보다 먼저 지어졌을 테니 오른쪽 아래가 큰 것으로 생각할 수 있다.
- target(MEDV) & LSTAT

관계가 딱봐도 있어보인다.
상관계수를 구해서 어디다 쓰는지 상관계수가 높은 두 변수가 있으면 그중에 하나를 버려도 되는건가?
차원 축소에 쓰는건지 아니면 그냥 데이터가 어떤지 알아보는 용도로만 쓰는 건지?
데이터 전처리 중 결측치, 이상치 처리 하고.
그 이후에 해야 할 일은 뭐가 있는지. 변수를 transform하고, 차원 축소가 가능하다면 차원 축소하는 것 외에?
####### 정리 ##########
# 결측치 확인
df.isnull().sum()
# row들의 합이 column기준으로 정렬됨.
# 이상치 확인
plt.boxplot(df.iloc[:, "Col"])
# whisker를 넘는 이상치 제거
np.percentile(arr, %point)
# %point percentile을 구한다.
# index dropping
df.drop(index, axis = 0, inplace = True)
# inplace = True라면 df에 다시 저장됨, inplace = False라면 return값을 주나봄.
# df에서 유일한 값들 개수 세기
df.column.value_counts()
# 피어슨 상관계수
corr_df = df.corr()
# df 내에 숫자로 표현되어 있지만 연속형이 아닌 변수들은 따로 제거해줘야 함.
# boolean mask
boston_df[(boston_df.RAD<5) & (boston_df.TAX>700)]
# index들에 대한 boolean mask를 만드는 듯'실습' 카테고리의 다른 글
| 실습 - sklearn 데이터셋 : Breast cancer (2) (0) | 2021.01.15 |
|---|---|
| 실습 - sklearn 데이터셋 : Breast cancer (1) (0) | 2021.01.15 |
| 실습 - sklearn 데이터셋 : Boston (2) (0) | 2021.01.13 |
